Quickstart Guide
Welcome to the Quickstart Guide for our API. This document will guide you through the initial setup, authentication, and making your first Completion API request.
Completion API
Completion API helps user to get LLM(Large Language Model) generated output for the query that is sent to the LLM. Each LLM has it’s own context length limit. Context Length defines the input and output token length. The input(query) passed to the LLM is the prompt. Prompt needs to be in detail for a detailed response. Generalised prompt would provide a generalised response. The Completion API endpoint uses various skill parameters which can be user configured to generate the response accordingly. The API request samples for HTTP Request and Python Request is given below.
To obtain the <api_key>, follow the instructions in the below section.
Authentication with API Key
To authenticate your request, creation of an <api_key> is needed, as explained in the next section.
Generate API Key using Web UI
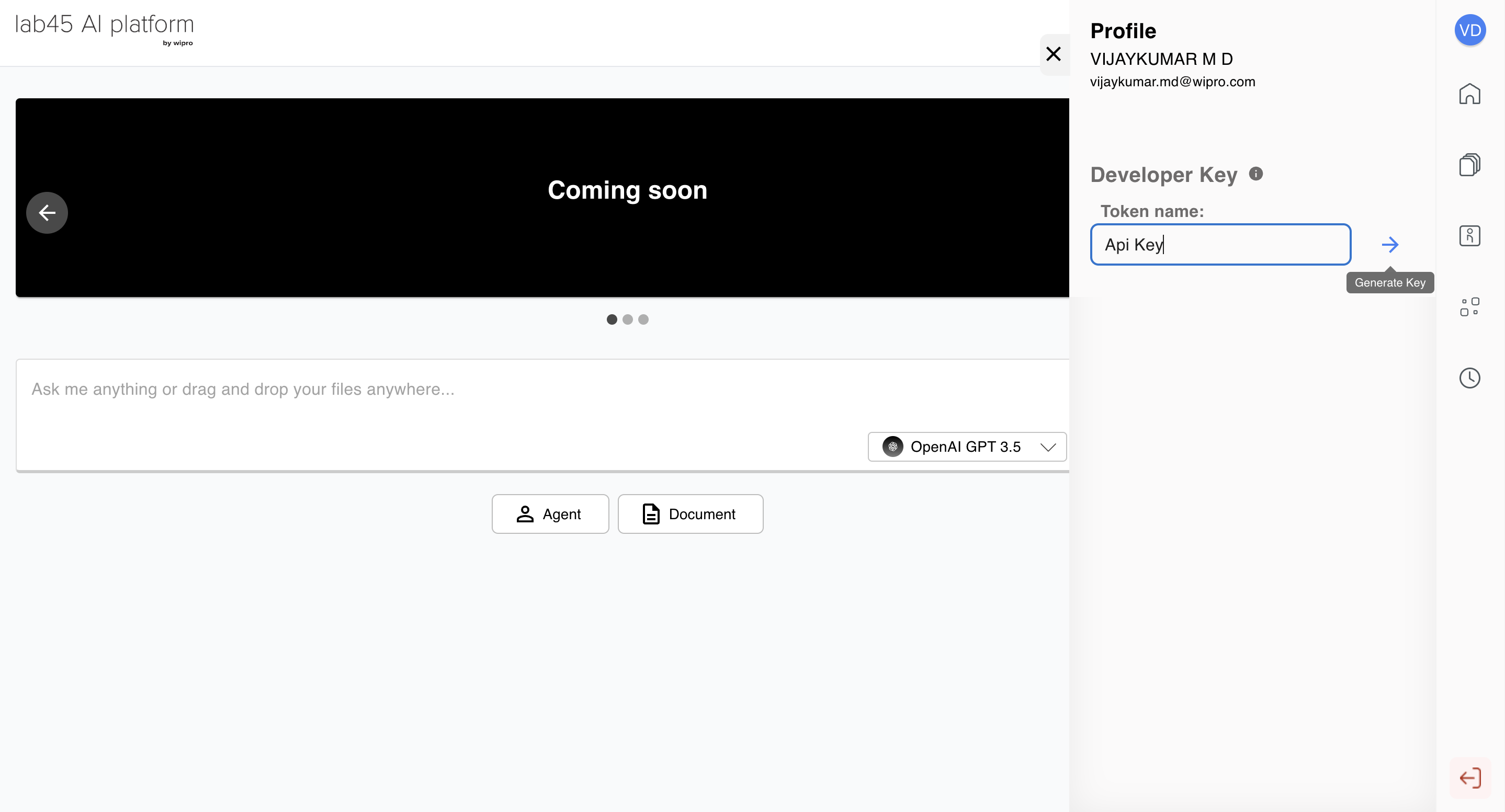
The <api_key> can be generated from our Web UI. The <api_key> can be copied from the user profile section as shown in the image by providing a <Token name>.
Please copy <api key> as shown below.
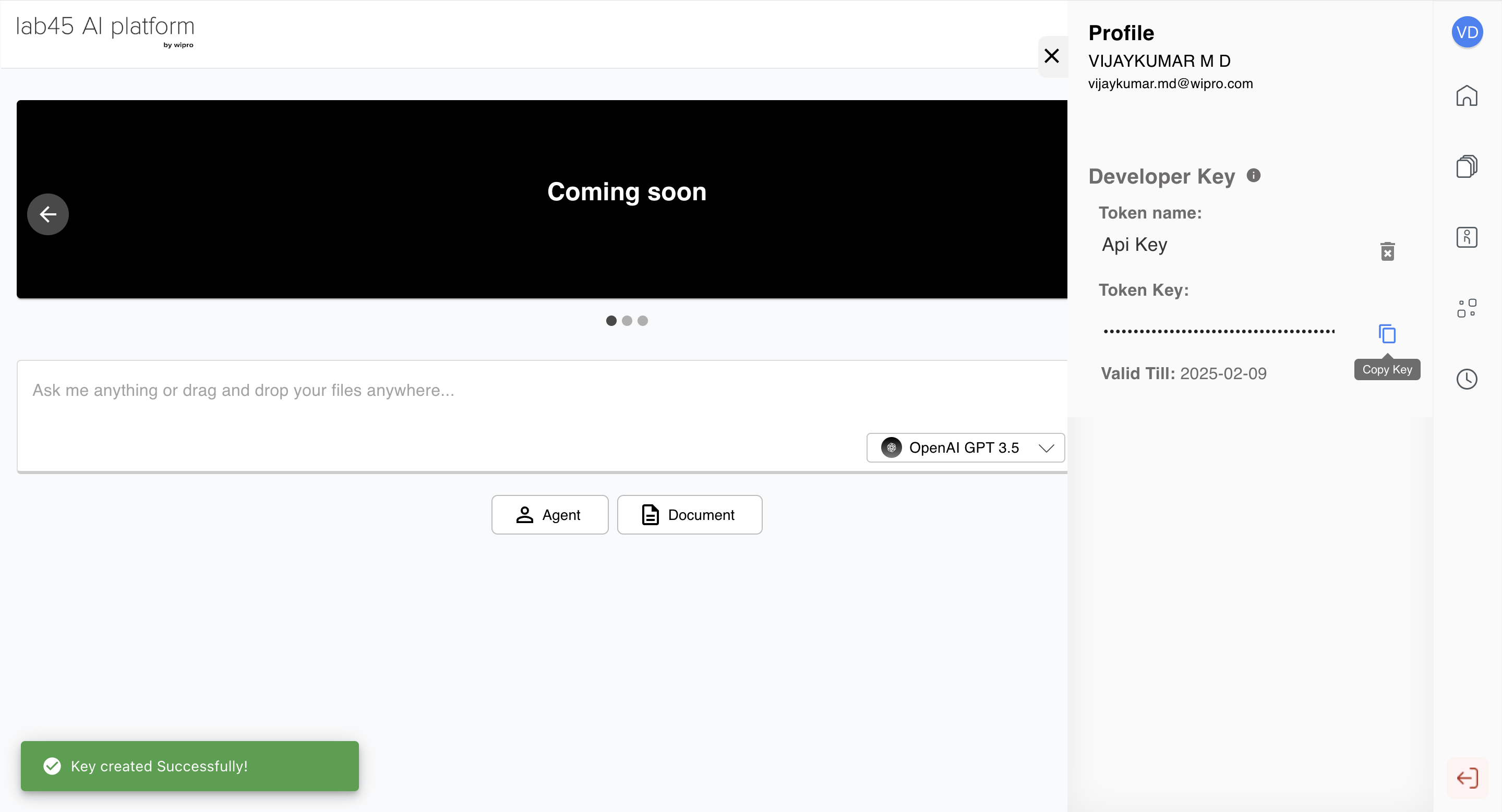
Managing your API Key
The <api_key> is valid for 30 days only. User can have only one <api_key> at a time. There will be an option to the user to see the existing <api_key> and delete the <api_key>. If an active <api_key> already exists for the user, the creation <api_key> will return an error. To create a new user <api_key>, you should delete the existing <api_key> if available. To use the <api_key>, you need to copy it somewhere safe and use it in the client code you are developing. Whenever the <api_key> is created, existing group of the user will be captured. On user group change you must create a new <api_key>.
HTTP Request
POST /v1.1/skills/completion/query HTTP/1.1
Content-Type: application/json
Accept: text/event-stream, application/json
Authorization: Bearer `<api_key>`
Host: api.lab45.ai
Content-Length: 148
{
"messages": [
{
"content": "What is a cat?",
"role": "user"
}
],
"skill_parameters": {
"model_name": "gpt-4",
"retrieval_chain": "custom",
"max_output_tokens": 256,
"temperature": 0,
"top_p": 1,
"frequency_penalty": 0,
"presence_penalty": 0,
"emb_type": "openai",
"top_k": 5,
"return_sources": false
}
}
All the skill_parameters can be referred from here. The messages section has role and content. The role represents the various roles used in interactions with the model.
Roles:
It can be any one as defined below -
- SYSTEM: Defines the model's behavior. System messages are not accepted here, as agent instructions default to system messages for agents.
- ASSISTANT: Represents the model's responses based on user messages.
- USER: Equivalent to the queries made by the user.
- AI: Interchangeably used with `ASSISTANT`, representing the model's responses.
- FUNCTION: Represents all function/tool call activity within the interaction.
Content:
Content is the user prompt/query. Detailed prompt helps in getting the relevant response. As per above content (what is a cat?), LLM will give generalised response as of what a cat is. But if we prompt the LLM with a specific cat (example - what is a persian cat?Give me a detailed response), the final response will be more specific to the type of cat provided by user in prompt.
Python Request
import requests
completion_endpoint = f"https://api.lab45.ai/v1.1/skills/completion/query"
headers = {
'Content-Type': "application/json",
'Accept': "text/event-stream, application/json",
'Authorization': "Bearer <api_key>"
}
payload =
{
"messages": [
{
"content": "What is a cat?",
"role": "user"
}
],
"skill_parameters": {
"model_name": "gpt-4",
"retrieval_chain": "custom",
"max_output_tokens": 256,
"temperature": 0,
"top_p": 1,
"frequency_penalty": 0,
"presence_penalty": 0,
"emb_type": "openai",
"top_k": 5,
"return_sources": False
}
}
response = requests.post(completion_endpoint, headers=headers, json=payload)